Never miss an update ! Subscribe to our Blog to receive the latest news and valuable insights














Behind the Scenes of Scraping Engineering with Fabien Vauchelles


The art of web scraping has become increasingly sophisticated, with websites employing advanced measures to keep their information private. As the demand for publicly available data continues to grow, it’s crucial to have a team of experts who can navigate this complex landscape with ease.
At Wiremind, we’re proud to have a team of dedicated professionals who specialize in the field of web scraping. Our experts stay ahead of the game by constantly updating and refining our scraping and anti-ban framework. This ensures that we can provide our clients with reliable and valuable data, no matter the level of complexity involved.
Insights from a Web Scraping Expert: An Interview with Fabien Vauchelles
But what does it take to be a web scraping professional? What are the key challenges involved in this field? To gain insights into these questions, we sat down with Fabien Vauchelles, a leading anti-ban specialist who recently joined Wiremind. In our interview, Fabien discussed his background and approach to web scraping and data extraction, shared his experience working on complex projects related to competition analysis, and revealed how he stays current with the latest advancements in the industry.
Can you walk us through your background and experience in software engineering?
As a lifelong code enthusiast, I have always been captivated by the magic of code. It allows you to create, analyze, and collaborate, as well as to unravel the mysteries of complex systems through reverse engineering. With a Master’s degree in Computer Science and extensive entrepreneurial experience, I have honed my skills in both academic and real-world settings. Over the years, I have founded three successful companies, including Zelros, which I left in June 2022 to pursue my true passion: web scraping. Prior to my departure as CTO, Zelros had grown into a thriving global organization with over 80 employees in multiple countries. I am proud to have been a part of its tremendous success.
How did you first get involved in web scraping and data extraction?
In 2013, I immersed myself in the world of web scraping. I had previously created spider programs but had never attempted to gather large amounts of data. My goal was to use machine learning algorithms to analyze millions of career paths and predict if individuals were likely to change jobs. To accomplish this, I needed to scrape millions of public profiles from a well-known professional networking platform. Although the site had some anti-bot measures in place, they were not enough to ultimately limit my requests.
In response, I developed Scrapoxy, a solution that launches thousands of proxies on cloud providers to form a massive pool of IP addresses. As the tool is open-source, it has been adopted by many companies to handle high volumes of data in a production setting.
What draws you to this field?
Web scraping is often misunderstood by the general public. While extracting data from a website may seem simple, the reality of automation and scaling the process is much more complex. Websites employ advanced anti-scraping measures that are invisible to human users but can effectively block automated bots.
There are several challenges in the field of web scraping, including bypassing these protections, scaling data retrieval, avoiding interference, and storing large amounts of data. The biggest challenge of all, however, is bypassing the anti-scraping measures put in place by websites.
In your opinion, what have been the most significant changes in the scraping industry in the past decade?
Ten years ago, websites did not give much importance to their data. But as the number of internet users rose from 2 billion in 2010 to 5.5 billion by the end of 2022, and the cloud market grew five-fold, websites started to realize the value of their data.
This led to the emergence of data-focused companies and anti-bot measures by websites. The result was a cat-and-mouse game of constantly evolving scraping solutions and protections. Today, it is difficult to evade these protections, which has made web scraping a highly specialized field accessible only to experts. Some companies, like Wiremind, have chosen to build their own expertise in this technology to gain a competitive advantage and avoid detection by anti-bot measures.
Can you share some tips for keeping up with the latest developments in web scraping and data extraction?
In the current scenario, anti-bot measures employ advanced techniques such as analyzing navigation patterns, the technical components involved (operating system, SSL layer, browser), and traffic origin among others. Artificial Intelligence is used to detect any deviation from typical human behavior, thereby making it challenging to carry out web scraping without being detected.
To avoid getting banned, it’s crucial to ensure that the web scraping infrastructure is highly consistent and replicates human-like behavior as closely as possible. As for the specific methods employed, let’s just say that they are a closely guarded secret.
Is web scraping considered legal?
The legality of web scraping is a constantly evolving issue. While ten years ago, the boundaries were not well defined, the situation has changed significantly in recent years. In the United States, the Computer Fraud and Abuse Act (CFAA) provides guidance on the use of data and establishes clear guidelines for web scraping. This act states that if data is publicly accessible without any access restrictions, such as login, it can be used by anyone, as long as it is not private information protected by regulations like the General Data Protection Regulation (GDPR).
Over the years, there have been numerous cases that have helped shape the understanding of web scraping legality, such as hiQ Labs, Inc. v. LinkedIn Corp, Sandvig v. Barr, and Meta Platforms v. BrandTotal Ltd. These cases have reinforced the principle established by the CFAA and further defined the boundaries of acceptable web scraping practices.
Mastering the art of web scraping for business success
Web scraping is a challenging industry that is in a state of constant change, but with the right approach and skilled team, it can provide valuable insights and contribute to business success. Fabien’s unparalleled expertise and unwavering commitment to the art of web scraping serve as a testament to the significance of this discipline in today’s digital landscape. With websites fortifying their defenses against scraping, companies like Wiremind require the services of highly skilled experts who can rise to the challenge.
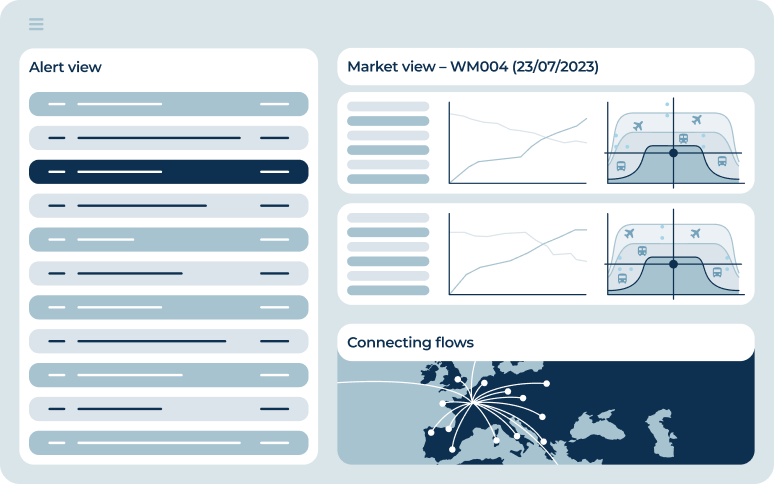
With a wealth of experience in the field of web scraping, Fabien Vauchelles has turned his attention to a new challenge – revolutionizing the transportation industry through competition tracking. As part of Wiremind’s innovative solutions, CAYZN Tracking utilizes the capability of web scraping technology to furnish businesses with up-to-the-minute insights and thorough data analysis, enabling them to maintain their edge over competitors and maximize their revenue uplift.
The multi-step approach to web scraping employed by CAYZN Tracking ensures that the data meets the highest standards of quality and comprehensiveness, with a 97% success rate. From defining the scraping perimeter to delivering processed data, the team at Wiremind is dedicated to providing clients with valuable, reliable data.
Are you ready to experience the cutting-edge technology that is changing the game in competition tracking? Get in touch with our team at info@wiremind.io for a free trial and see the results for yourself.

 Daria Jemli
Daria Jemli 


Discover how to digitize and optimize your offer with Wiremind


Wait a sec! Interested in a quick demo?
Witness how Wiremind's optimization solutions can supercharge your operations.
Book a demo